
Benchmark a Model¶
Have you ever trained multiple detection models and wondered which one performs best on your specific use case? Or maybe you've downloaded a pre-trained model and want to verify its performance on your dataset? Model benchmarking is essential for making informed decisions about which model to deploy in production.
This guide will show an easy way to benchmark your results using supervision. It will go over:
- Loading a dataset
- Loading a model
- Benchmarking Basics
- Running a Model
- Remapping Classes
- Visual Benchmarking
- Benchmarking Metrics
- Mean Average Precision (mAP)
- F1 Score
- Bonus: Model Leaderboard
This guide will use an instance segmentation model, but it applies to object detection, instance segmentation, and oriented bounding box models (OBB) too.
A condensed version of this guide is available as a Colab Notebook.
Loading a Dataset¶
Suppose you start with a dataset. Perhaps you found it on Universe; perhaps you labeled your own. In either case, this guide assumes you know of a labelled dataset at hand.
We'll use the following libraries:
roboflowto manage the dataset and deploy modelsinferenceto run the modelssupervisionto evaluate the model results
pip install roboflow supervision
pip install git+https://github.com/roboflow/inference.git@linas/allow-latest-rc-supervision
Info
We're updating inference at the moment. Please install it as shown above.
Here's how you can download a dataset:
from roboflow import Roboflow
rf = Roboflow(api_key="<YOUR_API_KEY>")
project = rf.workspace("<WORKSPACE_NAME>").project("<PROJECT_NAME>")
dataset = project.version("<DATASET_VERSION_NUMBER>").download("<FORMAT>")
If your dataset is from Universe, go to Dataset > Download Dataset > select the format (e.g. YOLOv11) > Show download code.
If labeling your own data, go to the dashboard and check this guide to find your workspace and project IDs.
In this guide, we shall use a small Corgi v2 dataset. It is well-labeled and comes with a test set.
from roboflow import Roboflow
rf = Roboflow(api_key="<YOUR_API_KEY>")
project = rf.workspace("fbamse1-gm2os").project("corgi-v2")
dataset = project.version(4).download("yolov11")
This will create a folder called Corgi-v2-4 with the dataset in the current working directory, with train, test, and valid folders and a data.yaml file.
Loading a Model¶
Let's load a model.
Roboflow supports a range of state-of-the-art pre-trained models for object detection, instance segmentation, and pose tracking. You don't even need an API key!
Let's load such a model with inference inference.
You can train and deploy a model without leaving the Roboflow platform. See this guide for more details.
To load a model, you can use inference:
Benchmarking Basics¶
Evaluating your model requires careful selection of the dataset. Which images should you use?Let's go over the different scenarios.
- Unrelated Dataset: If you have a dataset that was not used to train the model, this is the best choice.
- Training Set: This is the set of images used to train the model. This is fine if the model was not trained on this dataset. Otherwise, never use it for benchmarking - the results will seem unrealistically good.
- Validation Set: This is the set of images used to validate the model during training. Every Nth training epoch, the model is evaluated on the validation set. Often the training is stopped once the validation loss stops improving. Therefore, even while the images aren't used to train the model, it still indirectly influences the training outcome.
- Test Set: This is the set of images kept aside for model testing. It is exactly the set you should use for benchmarking. If the dataset was split correctly, none of these images would be shown to the model during training.
Therefore, an unrelated dataset or the test set is the best choice for benchmarking.
Several other problems may arise:
- Extra Classes: An unrelated dataset may contain additional classes which you may need to filter out before computing metrics.
- Class Mismatch: In an unrelated dataset, the class names or IDs may be different to what your model produces, you'll need to remap them, which is shown in this guide.
- Data Contamination: The
testset may not be split correctly, with images from the test set also present intrainingorvalidationset and used during training. In this case, the results will be overly optimistic. This also applies when very similar images are used for training and testing - e.g. those taken in the same environment, same lighting conditions, similar angle, etc. - Missing Test Set: Some datasets do not come with a test set. In this case, you should collect and label your own data. Alternatively, a validation set could be used, but the results could be overly optimistic. Make sure to test in the real world as soon as possible.
Running a Model¶
At this stage, you should have:
- A dataset of labeled images to evaluate the model.
- A model prepared for benchmarking.
With these ready, we can now run the model and obtain predictions.
We'll use supervision to create a dataset iterator, and then run the model on each image.
import supervision as sv
test_set = sv.DetectionDataset.from_yolo(
images_directory_path=f"{dataset.location}/test/images",
annotations_directory_path=f"{dataset.location}/test/labels",
data_yaml_path=f"{dataset.location}/data.yaml",
)
image_paths = []
predictions_list = []
targets_list = []
for image_path, image, label in test_set:
result = model.infer(image)[0]
predictions = sv.Detections.from_inference(result)
image_paths.append(image_path)
predictions_list.append(predictions)
targets_list.append(label)
import supervision as sv
test_set = sv.DetectionDataset.from_yolo(
images_directory_path=f"{dataset.location}/test/images",
annotations_directory_path=f"{dataset.location}/test/labels",
data_yaml_path=f"{dataset.location}/data.yaml",
)
image_paths = []
predictions_list = []
targets_list = []
for image_path, image, label in test_set:
result = model(image)[0]
predictions = sv.Detections.from_ultralytics(result)
image_paths.append(image_path)
predictions_list.append(predictions)
targets_list.append(label)
Remapping classes¶
Did you notice an issue in the above logic? Since we're using an unrelated dataset, the class names and IDs may be different from what the model was trained on.
We need to remap them to match the dataset classes. Here's how to do it:
def remap_classes(
detections: sv.Detections,
class_ids_from_to: dict[int, int],
class_names_from_to: dict[str, str],
) -> None:
new_class_ids = [
class_ids_from_to.get(class_id, class_id) for class_id in detections.class_id
]
detections.class_id = np.array(new_class_ids)
new_class_names = [
class_names_from_to.get(name, name) for name in detections["class_name"]
]
predictions["class_name"] = np.array(new_class_names)
Let's also remove the predictions that are not in the dataset classes.
Dataset class names and IDs can be found in the data.yaml file, or by printing dataset.classes.
import supervision as sv
test_set = sv.DetectionDataset.from_yolo(
images_directory_path=f"{dataset.location}/test/images",
annotations_directory_path=f"{dataset.location}/test/labels",
data_yaml_path=f"{dataset.location}/data.yaml",
)
image_paths = []
predictions_list = []
targets_list = []
for image_path, image, label in test_set:
result = model.infer(image)[0]
predictions = sv.Detections.from_inference(result)
remap_classes(
detections=predictions,
class_ids_from_to={16: 0},
class_names_from_to={"dog": "Corgi"},
)
predictions = predictions[np.isin(predictions["class_name"], test_set.classes),]
image_paths.append(image_path)
predictions_list.append(predictions)
targets_list.append(label)
Dataset class names and IDs can be found in the data.yaml file, or by printing dataset.classes.
Each model will have a different class mapping, so make sure to check the model's documentation. In this case, the model was trained on the COCO dataset, with a class configuration found here.
import supervision as sv
test_set = sv.DetectionDataset.from_yolo(
images_directory_path=f"{dataset.location}/test/images",
annotations_directory_path=f"{dataset.location}/test/labels",
data_yaml_path=f"{dataset.location}/data.yaml",
)
image_paths = []
predictions_list = []
targets_list = []
for image_path, image, label in test_set:
result = model(image)[0]
predictions = sv.Detections.from_ultralytics(result)
remap_classes(
detections=predictions,
class_ids_from_to={16: 0},
class_names_from_to={"dog": "Corgi"},
)
predictions = predictions[np.isin(predictions["class_name"], test_set.classes),]
image_paths.append(image_path)
predictions_list.append(predictions)
targets_list.append(label)
Visualizing Predictions¶
The first step in evaluating your model’s performance is to visualize its predictions. This gives an intuitive sense of how well your model is detecting objects and where it might be failing.
import supervision as sv
N = 9
GRID_SIZE = (3, 3)
target_annotator = sv.PolygonAnnotator(color=sv.Color.from_hex("#8315f9"), thickness=8)
prediction_annotator = sv.PolygonAnnotator(
color=sv.Color.from_hex("#00cfc6"), thickness=6
)
annotated_images = []
for image_path, predictions, targets in zip(
image_paths[:N], predictions_list[:N], targets_list[:N]
):
annotated_image = cv2.imread(image_path)
annotated_image = target_annotator.annotate(
scene=annotated_image, detections=targets
)
annotated_image = prediction_annotator.annotate(
scene=annotated_image, detections=prediction
)
annotated_images.append(annotated_image)
sv.plot_images_grid(images=annotated_images, grid_size=GRID_SIZE)
Here, predictions in purple are targets (ground truth), and predictions in teal are model predictions.
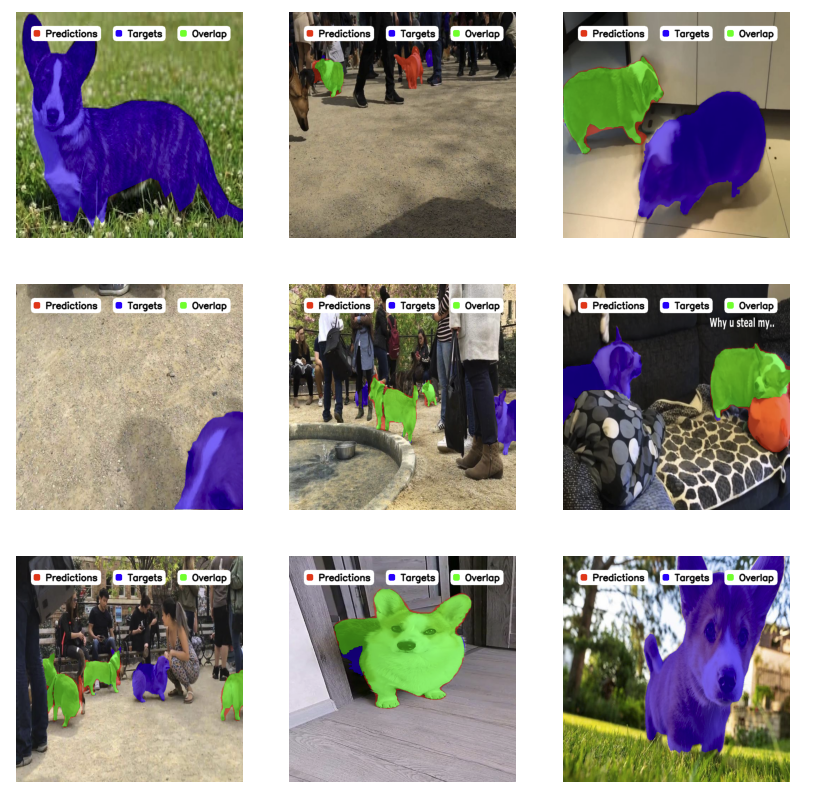
Tip
Use sv.BoxAnnotator for object detection and sv.OrientedBoxAnnotator for OBB.
See annotator documentation for even more options.
Benchmarking Metrics¶
With multiple models, fine details matter. Visual inspection may not be enough. supervision provides a collection of metrics that help obtain precise numerical results of model performance.
Mean Average Precision (mAP)¶
We'll start with MeanAveragePrecision (mAP), which is the most commonly used metric for object detection. It measures the average precision across all classes and IoU thresholds.
For a thorough explanation, check out our blog and Youtube video.
Here, the most popular value is mAP 50:95. It represents the average precision across all classes and IoU thresholds (0.5 to 0.95), whereas other values such as mAP 50 or mAP 75 only consider a single IoU threshold (0.5 and 0.75 respectively).
Let's compute the mAP:
from supervision.metrics import MeanAveragePrecision, MetricTarget
map_metric = MeanAveragePrecision(metric_target=MetricTarget.MASKS)
map_result = map_metric.update(predictions_list, targets_list).compute()
Try printing the result to see it at a glance:
MeanAveragePrecisionResult:
Metric target: MetricTarget.MASKS
Class agnostic: False
mAP @ 50:95: 0.2409
mAP @ 50: 0.3591
mAP @ 75: 0.2915
mAP scores: [0.35909 0.3468 0.34556 ...]
IoU thresh: [0.5 0.55 0.6 ...]
AP per class:
0: [0.35909 0.3468 0.34556 ...]
...
Small objects: ...
Medium objects: ...
Large objects: ...
You can also plot the results:
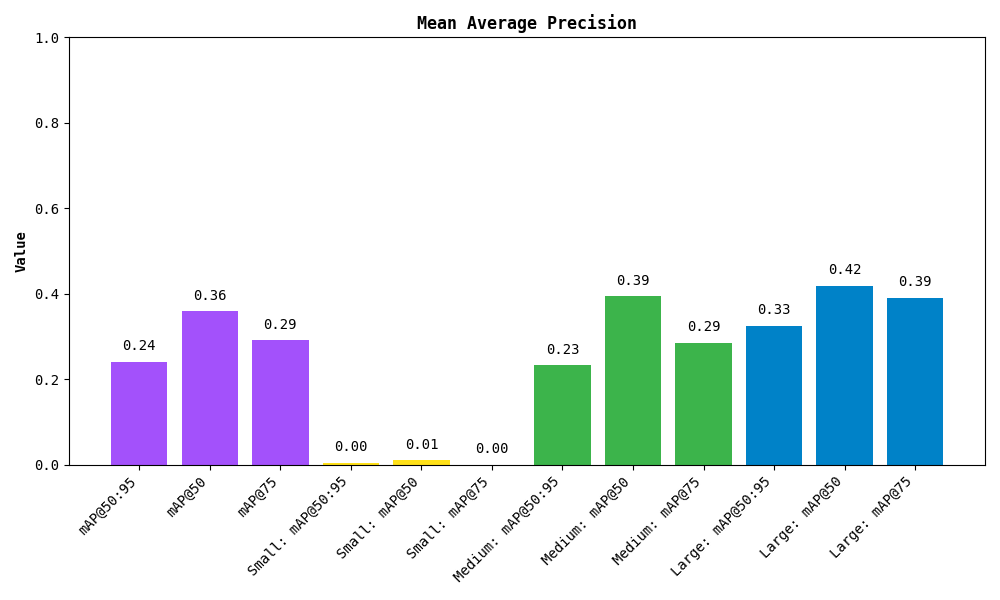
The metric also breaks down the results by detected object area. Small, medium and large are simply those with area less than 32², between 32² and 96², and greater than 96² pixels respectively.
F1 Score¶
The F1 Score is another useful metric, especially when dealing with an imbalance between false positives and false negatives. It’s the harmonic mean of precision (how many predictions are correct) and recall (how many actual instances were detected).
Here's how you can compute the F1 score:
from supervision.metrics import F1Score, MetricTarget
f1_metric = F1Score(metric_target=MetricTarget.MASKS)
f1_result = f1_metric.update(predictions_list, targets_list).compute()
As with mAP, you can also print the result:
F1ScoreResult:
Metric target: MetricTarget.MASKS
Averaging method: AveragingMethod.WEIGHTED
F1 @ 50: 0.5341
F1 @ 75: 0.4636
F1 @ thresh: [0.53406 0.5278 0.52153 ...]
IoU thresh: [0.5 0.55 0.6 ...]
F1 per class:
0: [0.53406 0.5278 0.52153 ...]
...
Small objects: ...
Medium objects: ...
Large objects: ...
Similarly, you can plot the results:
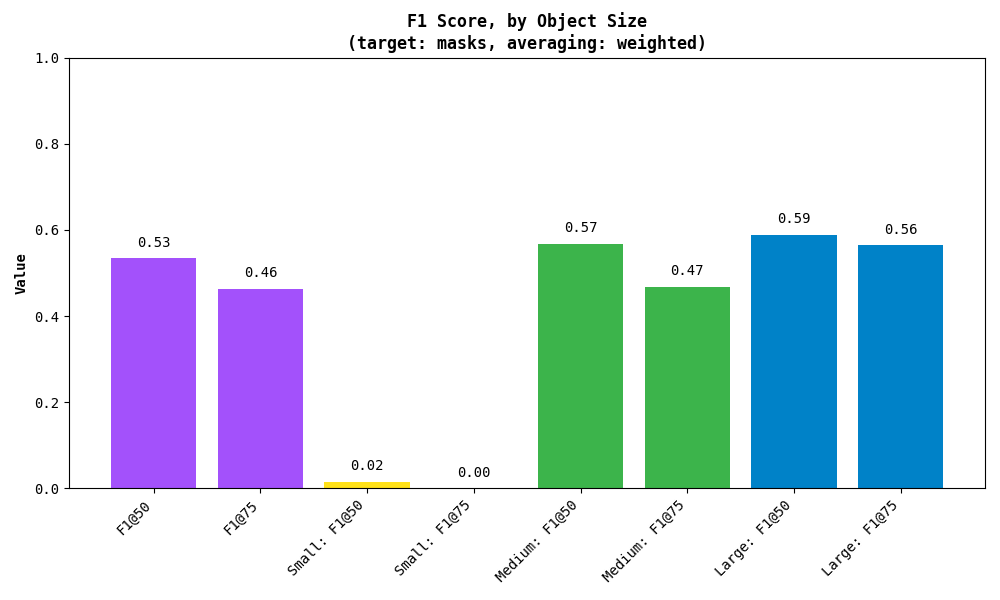
As with mAP, the metric also breaks down the results by detected object area. Small, medium and large are simply those with area less than 32², between 32² and 96², and greater than 96² pixels respectively.
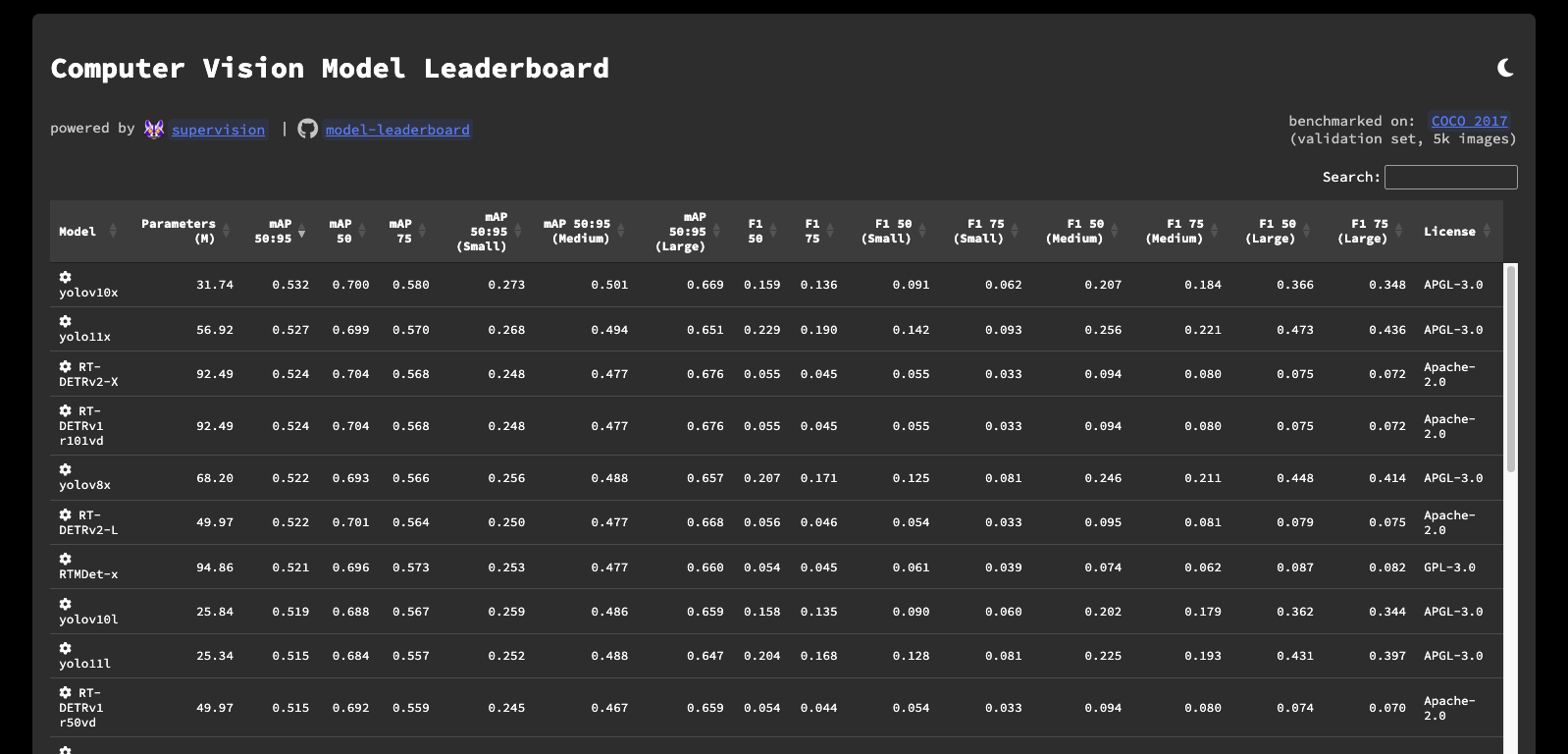
Model Leaderboard¶
Here to compare the basic models? We've got you covered. Check out our Model Leaderboard to see how different models perform and to get a sense of the state-of-the-art results. It's a great place to understand what the leading models can achieve and to compare your own results.
Even better, the repository is open source! You can see how the models were benchmarked, run the evaluation yourself, and even add your own models to the leaderboard. Check it out on GitHub!
Conclusion¶
In this guide, you've learned how to set up your environment, train or use pre-trained models, visualize predictions, and evaluate model performance with metrics like mAP, F1 score, and got to know our Model Leaderboard.
A condensed version of this guide is also available as a Colab Notebook.
For more details, be sure to check out our documentation and join our community discussions. If you find any issues, please let us know on GitHub.
Best of luck with your benchmarking!